
DR 101: Snapshots, Continuous Data Protection and Point in Time Recovery
By Joshua Stenhouse, Zerto Technical Evangelist
Snapshots are often used to replicate Virtual Machines (VMs) from a specific point in time and to maintain multiple recovery points in order to recover from a disaster. Snapshots can be performed at the VM level or at the Storage Area Network (SAN) level.
VM level snapshots are created in the hypervisor and they incur the biggest performance impact.It is therefore not recommended to create, remove or leave VM level snapshots running on production VMs during working hours for this reason. Any VM level snapshot-based replication system is usually configured to replicate daily or weekly, outside of working hours, to ensure no performance impact. Additionally, it can only replicate as often as the snapshots are configured to run. This often introduces complexity in trying to manage schedules so as not to conflict backup and replication schedules of the same VMs.
Some VM level replication solutions offer the feature of “continuous replication.” But this simply refers to a constantly running replication job that is forever creating, reading, consolidating and removing snapshots, and stunning the protected VM which nobody would want for production VMs.
Storage level snapshots incur less performance impact than VM level snapshots, but still require processing power in a storage controller and at scale can still start to degrade performance. The frequency at which storage level snapshots can be created is therefore still very much limited by the potential for performance impact. This means that storage snapshots are often taken every few hours to give a restorable point in time of the data which is then replicated to a recovery site.
With both types of snapshots, the recovery points available are often limited at best. Below is an example of a typical storage snapshot schedule with nightly backups which represent VM level snapshots:
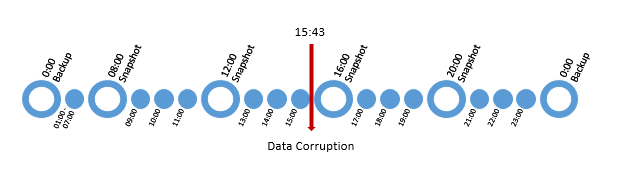
The main problem with snapshots is not only the potential for performance impact, it is the granularity of the points in time for recovery that they offer. If we take the above example of a data corruption at 15:43, then a VM level 24 hour snapshot based replication solution means you are going to potentially have nearly 16 hours of data loss, as you would have to restore a replicated snapshot from last night. The same example with storage based replication would result in data loss of nearly 4 hours. Both of which could result in a significant loss of valuable data for an organization.
With hypervisor-based replication used in continuous data protection (CDP) no snapshots are created on the protected VM, so no performance impact is ever introduced. Hypervisor based CDP also utilizes journal technology to keep a log of all of the changes occurring in a specified journal time frame, allowing recovery to points in time every few seconds for the length of the journal. This means that in the above example, the data could be restored to 15:42:50, just before the corruption occurred, significantly reducing the data loss and impact to the organization.
By utilizing journal technology, rather than VM level snapshots for point in time recovery, there are multiple benefits beyond simply the sheer number of points in time available.
They are:
- Storing multiple snapshots on replica VMs incurs a significant VM performance penalty if you attempt to power on the replica VM. Full performance can only be achieved once all of the snapshots have been consolidated, which significantly increases the RTO. With journal based protection, the journal is only used until you commit to the point in time selected, without the performance impact of many snapshots.
- Using snapshots on replicated VMs gives no way of controlling the total space used for snapshots, or the ability to store the data change on a separate datastore. This makes it un-scalable in terms of being able to set SLAs and define maximum limits on the data space used by the snapshots. Furthermore, the data is always stored with the replica VM. With journal based protection you can place the journal on any datastore and place a maximum size limits and warnings; so as not to fill the datastore which could otherwise break replication and recover.
- With storage based replication there is often significant overhead on the storage arrays for replication reserves; which can be 20-30% on both source and target storage in many cases. With journaling technology, no extra space is used in the source storage as no snapshots are created.Only 7-10% of the target storage is typically used for the changed data. freeing up significant amounts of disk space. This is due to journals being able to dynamically reclaim unused space and only use what they need. If the journal becomes full then it simply starts to reduce the number of recovery points available, or increases the journal space usage depending on your configuration. In contrast, storage based snapshots running out of replica reserve which can often break production performance, will cease replication operations and render the recovery broken.
I hope this has given you a good insight into snapshots and covered the main points you should take into consideration when evaluating whether to use snapshots or CDP for replication and point in time recovery.
Become even more knowledgeable with our Disaster Recovery Essential Guide!
